
You Have Heard of DevOps and SecDevOps, Well Now It Is Time for DataOps!
While I was getting my Masters a question was proposed to our professor, “How do we take the models we are building and put them into a production environment?” The answer was a bit underwhelming. We were told that we would simply hand over the model to a developer who would refactor our messy code and place it into production. Well I am calling shenanigans. I mean I am sure there is a company somewhere where there are willing developers to take my code, clean it, and build a data pipeline around it, but I have a feeling this the exception and not the norm.
My second problem with this statement is it treats models as fire and forget. While a data scientist can build a model and send it off into the wild and move on to the next project, it is probably not a good idea. This is because at its most base form a model is just a simplification of reality and it is build on assumptions. If our assumptions are wrong the model will be wrong. Once the model is in production it needs to be monitored to ensure the assumptions made while building the model hold true, and if not the model needs to be adjusted. Moreover, the world is not a static environment nor should our models be. For a model to be relevant it needs to be adjusted and updated. In a fire and forget model deployment the model is never adjusted or updated.
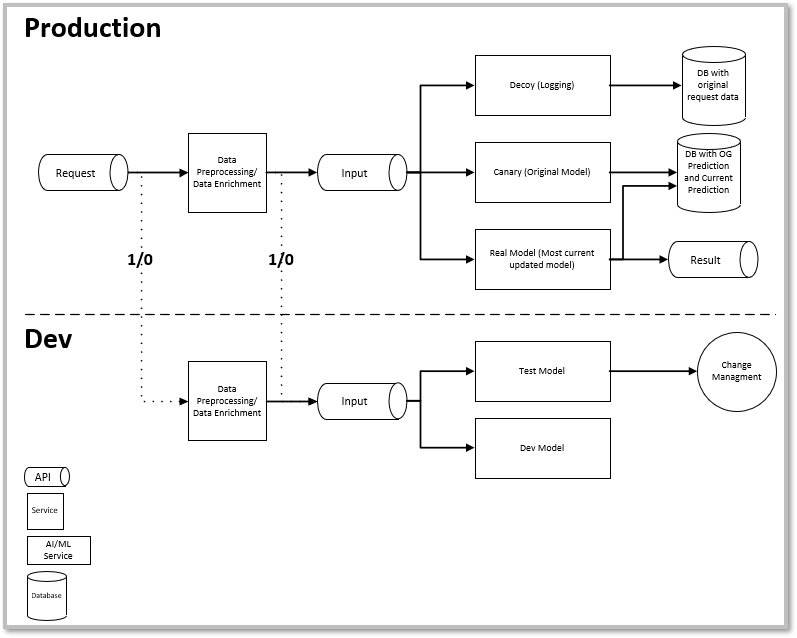
We need a method where models can provide quick predictions, these predictions and raw data are logged, model drift can be monitored, and new models can be tested and when ready integrated. We need DATAOPS. An example of a DataOps architecture is shown below. Admittedly most of this is not my idea and was presented in the book The Rendezvous Architecture for Machine Learning by Ted Dunning and Ellen Friedman.
-
We start with a request. I envision that as part of a larger ETL process where a REST API request is sent to our model. For ease of understanding for now I staying above the “Production” line. I will come back to the portions below the “Dev” line later in the article.
-
Once the model receives the request the data preprocessing and data enrichment is completed. This can either be done in the application or through another REST request. To see what method works best in any specific environment testing would be required.
-
Now the data is in the proper format for the model three things will happen. For me this is perhaps the most important part of the DataOps concept. The data is not just sent to a model for a prediction and sent back out, but rather the data is sent to three different bins for processing. They are the Log, Canary Model, and the Real Model bins.
-
Real Model: The real model bin is where the model conducts its prediction and returns the prediction to the requestor via the API. A copy of the prediction will be saved in the Canary Model.
-
Canary Model: This bin is also a historical record of sorts. This bin will produce and store the prediction using the current data, but only using the original model. It is now possible to monitor our model drift as we can see the prediction using the original model and can compare it against the current live model. This is even more important for active learning models where user feedback is incorporated into the model. We are now able to have a near real time view of the model drift and we are able to make corrections to the model if required. This Canary Model can also be used to predict and store the results from all model updates. This could provide valuable insight to overall model performance and how model adjustments have impacted that performance.
-
Log bin : This bin is a log of the original data coming into the model, and a record of the data transformations which took place prior to the model conducting its prediction. Consider this nothing more than a historical record of the data coming into the model. This data can be revisited later for a deeper analysis.
-
-
For the Dev side of the line there are a couple options. Once the request is made on the production side, a copy of the request can be sent to the dev side. This request can be sent prior to the data preprocessing step or afterwards. The key point is that the dev side has near real time data coming in which can be used to further develop models.
-
As the data scientist now has live data to incorporate into model test and development, model improvements are made. Once these model improvements are ready to go live on the production side they go through the typical change management process. At this point the “old” model is moved to the Canary bin, and the “new” model become the real model. And thus the circle of data continues.
The easy part is diagraming out this concept. It takes a full team to actually implement this and test it to ensure that the complexity does not have a negative impact on the user experience. This is not an easy task, but when successfully complete the data scientist is now an active participant in the model deployment process, model drift between versions can be accounted for, a historical log of all requests is made, and oh yea the customer gets an accurate prediction they requested.
So if you are now intrigued into DataOps and the Rendezvous Architecture and how it can be used successfully I encourage you to take a look at Machine Learning Logistics by Jan Teichmann.
“We are moving slowly into an era where Big Data is the starting point, not the end.” – By Pearl Zhu, Digital Master