
Project Background
The purpose of this project was to take NFL game data from the now deprecated NFL API extract the details, conduct required data transformations and store the data in AWS Redshift. I was going to use this project to enable me to further analyze NFL game data; however, the NFL has since restricted access to this dataset. As such it is impossible to replicate this project.
The end goal of this project is to have a database where it is possible to conduct complex aggregate based queries against NFL data. To do this I used game data available from the NFL API, but as I stated earlier this API is no longer available to unregistered users.
This project used several technologies:
- Apache Airflow for the workflow management
- AWS Lambda to fetch data, extract and transform data
- AWS s3 for JSON storage
- AWS Redshift used as the analytical database
- Python was used as the primary programming language
The GitHub for this project is located here: NFL-Data-Pipeline
Project Datasets
The NFL datasets used in this picture come from the NFL Teams, Schedule, Coaches, Players, and Games come from the NFL endpoint.
Teams: The team data by year use to be found at https://www.nfl.com/feeds-rs/teams/
- Season: Season of the record
- Team ID: A unique ID for each team in the NFL.
- Team Abbreviation: Commonly used team abbreviation for example the Denver Broncos is "DEN".
- City/State: How the team is identified by location for example the Denver Broncos is "Denver".
- Full Name: The full name of the team.
- Nickname: Commonly nickname for the team.
- Team Type: Used to annotate if the team is a regular season team or the "Pro Bowl Team"
- Conference Abbreviation, ID, and Full Name
- Division Abbreviation, ID, and Full Name
- Year Founded
- Stadium name
- Ticket Phone Number
- Team URL
- Team Ticket URL
Schedule: The full schedule for the entire year was posted at https://www.nfl.com/feeds-rs/schedules/
- Season:
- Season Type: This annotates if the is a preseason, regular season or post season game.
- Week:
- Game ID: A unique ID used for each game.
- Game Key: A unique ID used for each game
- Game Time Eastern:
- Game Time Local:
- ISO TIME:
- Home Team ID:
- Visitor Team ID:
- Home Team Abbr:
- Visitor Team Abbr:
- Home Display Name:
- Visitor Display Name:
- Home Nick Name:
- Visitor Nick Name:
- Game Type:
- Week Name Abbrievation:
- Week Name:
- Visitor Team, Season, Team ID, City/State, Full Name, Nickname, Team Type, Conference Abbr, Division Abbrievation:
- Home Team, Season, Team ID, City/State, Full Name, Nickname, Team Type, Conference Abbr, Division Abbrievation:
- Site ID, Site City, Site Full Name, Site State, Roof type, and network channel:
Coaches : Information for each coach for each team by year use to be found at https://www.nfl.com/feeds-rs/coach/byTeam/
- NFLID: This is a unique ID used for coaches and players.
- Status: This indicates if the coach or player is active, retired, or free agent.
- Display Name:
- First Name:
- Last Name:
- ESBID: This is a unique ID used for coaches and players. This number is also used to generate the url for the picture used.
- Birthdate:
- Home Town:
- Is Deceased:
- Current Status: This indicates if the coach or player is active, retired, or free agent.
- College ID:
- College Name:
Players: Player information was found at https://www.nfl.com/feeds-rs/playerStats/
- NFLID: This is a unique ID used for coaches and players.
- Status: This indicates if the coach or player is active, retired, or free agent.
- Display Name:
- First Name:
- Last Name:
- ESBID: This is a unique ID used for coaches and players.
- GSISIS: This is a unique ID used for coaches and players.
- Middle Name:
- Suffix:
- Birth Date:
- Home Town:
- College ID:
- College Name:
- Position Group:
- Position:
- Jersey Number:
- Height:
- Weight:
- Team ID:
Games: The site to get detailed game information was found at https://www.nfl.com/feeds-rs/boxscorePbp/
- Season:
- Season Type: This indicates if the game is Preseason, Regular Season, or Post Season.
- Week:
- Game Id: This is a unique identifier for each game.
- Game Key: This is a unique identifier for each game.
- Game Date:
- ISO Time:
- Home Team ID: This the unique id for the home team
- Visitor Team ID: This is the unique id for the visitor team.
- Game Type: This is the common name for the game, it can be Preseason, Regular Season, or even SB for Superbowl.
- Phase: This indicates the current phase of the game. Unless the game is currently in session this should read "FINAL"
- Visitor Team Score Total:
- Visitor Team Score Q1:
- Visitor Team Score Q2:
- Visitor Team Score Q3:
- Visitor Team Score Q4:
- Visitor Team Score OT:
- Home Team Score Total:
- Home Team Score Q1:
- Home Team Score Q2:
- Home Team Score Q3:
- Home Team Score Q4:
- Home Team Score OT:
- Drive Sequence: This is a unique identifier for the drive for this specific game.
- Play ID: This is a unique identifier for this play for this drive sequence.
- Scoring: This is a Boolean value for this play resulted in a scoring drive.
- Scoring Team ID: This will indicate the ID of the scoring team if the play resulted in a score.
- Possession Team ID: This indicates the ID of the team that currently on offense.
- Play Type: This is a categorical variable which indicates the play type. Most common forms are Pass, Rush, and Kick-off.
- Quarter:
- Down:
- Yards to Go:
- First Down or Touch Down:
- Play Stat Sequence: As a play can have multiple participants this provides a unique value for each portion of a play.
- Stat ID: This is the Stat ID of the play. This can be cross referenced in the stat_codes.csv, which will be included as a dimension table.
- NFLID: This the unique ID of the player involved with this specific portion o f the play.
- Yards: This is the number of yards this player is responsible for. If they player had no yards the value will be zero.
- Play Description: This is the number of yards this player is responsible for. If they player had no yards the value will be zero.
- Play Video: If the play contains a highlight video there will be a direct link to the video here, this is an example.
STAT ID: This is a CSV containing the STAT ID codes and descriptions for each stat used in a game. The CSV can be seen here STAT ID. The fields are described below.
- STAT ID: This is the unique identifier for each stat.
- Name: This is the common name for the stat.
- Comment: This is a detailed description of the stat.
Project Tools
This project incorporated tools from both the Udacity course as well as other AWS offerings. The tools used included:
- Python
- AWS S3
- AWS Lambda
- AWS Redshift
- Apache Airflow
Python: Python was used to access the NFL endpoints and conduct the data transformations to load the data into Redshift staging tables as well as the fact and dimension tables. Python code was used on a local computer to initiate the data ingest and transformation, in AWS Lambda to access multiple endpoints simultaneously, and in Apache Airflow.
AWS s3: s3 cloud storage was used as a temporary storage location for the team data json, NFL schedule json, coach data json, player data json, and game data json files.
AWS Lambda: Lambda was used for a majority of the data transformation. Lambda is serverless in nature and can be configured to run python code. Lambda works very well on small pieces of code which can be fully executed in less than fifteen minutes. As the transformations for the NFL data was simple, but there were many files to transform Lambda was used to parallelize these data transformations. When a json file was loaded into an s3 bucket the appropriate Lambda would execute.
AWS Redshift: Redshift was used as the analytical database. Data was loaded into staging tables from s3 and then sql queries were used to move the data into the fact and dimension tables.
AWS Apache Airflow: Airflow was used to monitor and manage some of the data transformation workflows for this project.
Final Database Schema
The data model used is a simple star data model. This data model works well as it is easy to query with quick speeds. The table has not been taken to 3NF, while this increases redundancy it will result in faster return times on queries. Once the data has been preprocessed and placed in the correct s3 folder it can be copied into the the staging table. From the staging tables it will be inserted into the correct fact and dimension tables.
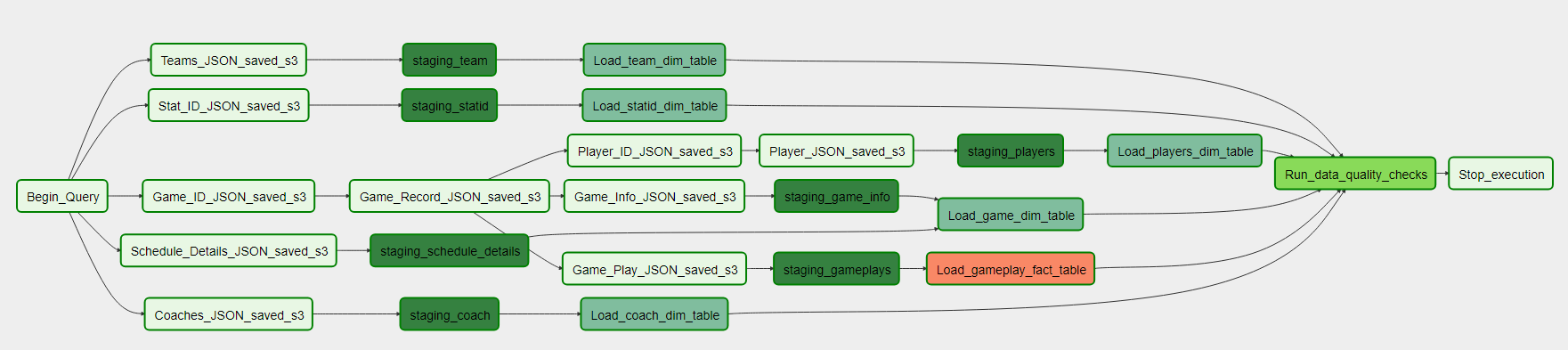
The mapping for S3 folder to staging table to fact or dim table is as follows:
s3://nfl-cap/coaches » coaches_staging » coaches_dim
s3://nfl-cap/gameinfo » gameinfo_staging » game_dim
s3://nfl-cap/schedules_details » schedules_details_staging » game_dim
s3://nfl-cap/gameplays » gameplays_staging » play_fact
s3://nfl-cap/player_info » player_info_staging » players_dim
s3://nfl-cap/statids/ » statid_codes_staging » statid_dim
s3://nfl-cap/teams » team_staging » team_dim
Staging Tables
There are seven staging tables for this project. They can be seen in this PDF
Coaches Staging Table
| Field | Data Type |
|---|---|
| coach_id | varchar |
| season | int |
| week | varchar |
| display_name | varchar |
| first_name | varchar |
| last_name | varchar |
| esbid | varchar |
| status | varchar |
| birthdate | date |
| hometown | varchar |
| collge | varchar |
| team_id | varchar |
| isdeceased | varchar |
| pic_url | varchar |
Game Info Staging Table
| Field | Data Type |
|---|---|
| game_id | varchar |
| season | int |
| season_type | varchar |
| week | varchar |
| game_key | varchar |
| game_date | date |
| game_time_iso | timestamp |
| vis_points_total | int |
| vis_points_q1 | int |
| vis_points_q2 | int |
| vis_points_q3 | int |
| vis_points_q4 | int |
| vis_points_ot | int |
| home_points_total | int |
| home_points_q1 | int |
| home_points_q2 | int |
| home_points_q3 | int |
| home_points_q4 | int |
| home_points_ot | int |
| win_team | varchar |
| lose_team | varchar |
| site_id | varchar |
| site_city | varchar |
| site_full_name | varchar |
| site_state | varchar |
| roof_type | varchar |
| phase | varchar |
Game Plays Staging Table
| Field | Data Type |
|---|---|
| game_id | varchar |
| week | varchar |
| drive_seq | varchar |
| play_id | varchar |
| play_stat_id | varchar |
| season | int |
| home_team | varchar |
| def_team | varchar |
| off_team | varchar |
| vis_team | varchar |
| penalty | varchar |
| scoring | varchar |
| scoring_team | varchar |
| play_type | varchar |
| quarter | varchar |
| down | int |
| yard_to_go | numeric |
| first_down | varchar |
| play_descript varchar | |
| play_vid | varchar |
| stat_id | varchar |
| yards | int |
| player_id | varchar |
| player_team | varchar |
Player Info Staging Table
| Field | Data Type |
|---|---|
| nfl_id | varchar |
| esb_id | varchar |
| gsis_id | varchar |
| status | varchar |
| display_name | varchar |
| first_name | varchar |
| last_name | varchar |
| middle_name | varchar |
| suffix | varchar |
| birth_date | date |
| home_town | varchar |
| college_id | varchar |
| college_name | varchar |
| position_group | varchar |
| position | varchar |
| jersey_number | varchar |
| height | int |
| weight | int |
| current_team | varchar |
| player_pic_url | varchar |
Statid Code Staging Table
| Field | Data Type |
|---|---|
| stat_id | varchar |
| name | varchar |
| comment | varchar |
Schedule Details Staging Table
| Field | Data Type |
|---|---|
| game_id | varchar |
| season | int |
| season_type | varchar |
| week | varchar |
| game_key | varchar |
| home_id | varchar |
| vis_id | varchar |
| game_type | varchar |
| week_name_abbr | varchar |
| week_name | varchar |
Team Staging Table
| Field | Data Type |
|---|---|
| team_id | varchar |
| season | int |
| abbr | varchar |
| citystate | varchar |
| full_name | varchar |
| nick | varchar |
| team_type | varchar |
| conference_abbr | varchar |
| division_abbr | varchar |
| year_found | int |
| stadium_name | varchar |
Fact and Dim Tables
There are five dimension tables and 1 fact table. They can be seen in this PDF
Coaches Dim Table
| Field | Data Type | Key |
|---|---|---|
| coach_id | varchar | PRIMARY |
| season | int | PRIMARY |
| week | varchar | PRIMARY |
| display_name | varchar | |
| full_name | varchar | |
| last_name | varchar | |
| esbid | varchar | |
| birthdate | date | |
| hometown | varchar | |
| college | int | |
| team_id | varchar | |
| isdeceased | varchar | |
| pic_url | varchar |
Players Dim Table
| Field | Data Type | Key |
|---|---|---|
| nflid | varchar | PRIMARY |
| esbid | varchar | |
| gsisid | varchar | |
| status | varchar | |
| display_name | varchar | |
| first_name | varchar | |
| last_name | varchar | |
| middle_name | date | |
| suffix | varchar | |
| birthdate | date | |
| hometown | varchar | |
| college_id | varchar | |
| college | varchar | |
| position_group | varchar | |
| position | varchar | |
| jersey_number | varchar | |
| height | int | |
| weight | int | |
| current_team | varchar | |
| player_pic_url | varchar |
Game Dim Table
| Field | Data Type | Key |
|---|---|---|
| game_id | varchar | PRIMARY |
| season | int | |
| season_type | varchar | |
| week | varchar | |
| game_key | varchar | |
| game_date | date | |
| game_time_iso | timestamp | |
| vis_points_total | int | |
| vis_points_q1 | int | |
| vis_points_q2 | int | |
| vis_points_q3 | int | |
| vis_points_q4 | int | |
| vis_points_ot | int | |
| home_points_total | int | |
| home_points_q1 | int | |
| home_points_q2 | int | |
| home_points_q3 | int | |
| home_points_q4 | int | |
| home_points_ot | int | |
| win_team | varchar | |
| lose_team | varchar | |
| site_id | varchar | |
| site_city | varchar | |
| site_full_name | varchar | |
| site_state | varchar | |
| roof_type | varchar | |
| game_phase | varchar | |
| week_name_abbr | varchar | |
| week_name | varchar | |
| game_type | varchar | |
| home_id | varchar | |
| away_id | varchar |
Team Dim Table
| Field | Data Type | Key |
|---|---|---|
| team_id | varchar | PRIMARY |
| season | int | |
| abbr | varchar | |
| citystate | varchar | |
| full_name | varchar | |
| nick | varchar | |
| team_type | varchar | |
| conference_abbr | varchar | |
| division_abbr | varchar | |
| year_found | int | |
| stadium_name | varchar |
Stat ID Dim Table
| Field | Data Type | Key |
|---|---|---|
| stat_id | varchar | PRIMARY |
| name | int | |
| comment | varchar |
Play Fact Table
| Field | Data Type | KEY |
|---|---|---|
| guid | sequence | PRIMARY |
| game_id | varchar | |
| week | varchar | |
| drive_seq | varchar | |
| play_id | varchar | |
| play_stat_id | varchar | |
| season | int | |
| home_team | varchar | |
| def_team | varchar | |
| off_team | varchar | |
| vis_team | varchar | |
| penalty | varchar | |
| scoring | varchar | |
| scoring_team | varchar | |
| play_type | varchar | |
| quarter | varchar | |
| down | int | |
| yard_to_go | numeric | |
| first_down | varchar | |
| play_descript | varchar | |
| play_vid | varchar | |
| stat_id | varchar | |
| yards | int | |
| player_id | varchar | |
| player_team | varchar |
Project Process
There are two primary problems with this dataset. The first is gathering the data and the second is the primary dataset called games is a heavily nested json document and will require preprocessing before it can be loaded into a staging table. To gather a all the required json files the following process was used.
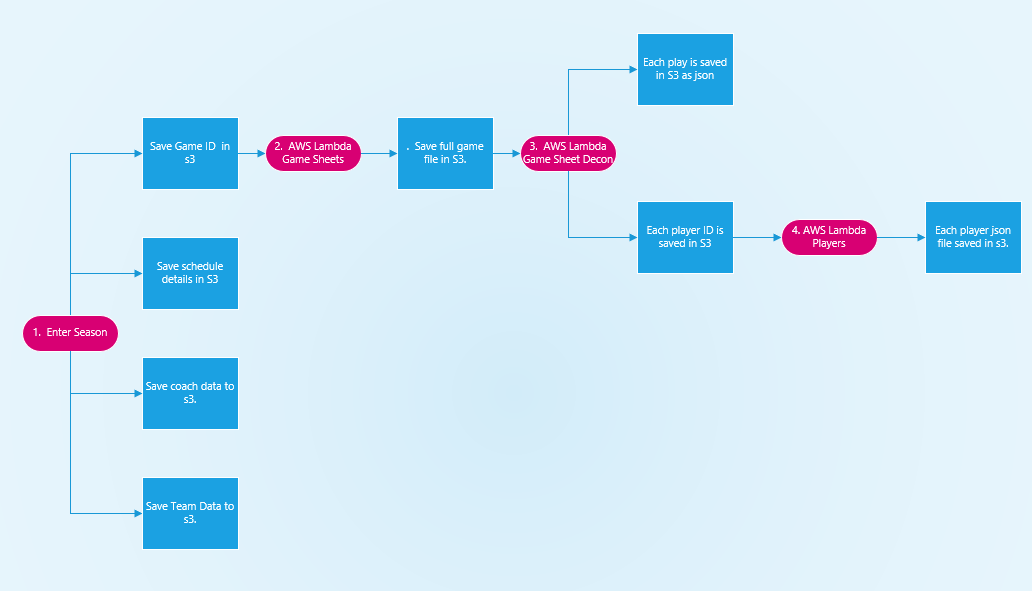
Step 1
The data gathering process is initiated with a python script where the user enters in the season of the NFL data they want to enter into the database. The script code can be viewed in the access_raw_data Jupyter notebook. This script will execute four function functions
- The script will go to https://www.nfl.com/feeds-rs/schedules/
.json and do the following: - Save each Game ID as a separate JSON in s3
- Save Game detailed information in s3
-
For each team in the NFL schedule for that season the script will go to https://www.nfl.com/feeds-rs/teams/
.json and get detailed information for each team for the season selected. Each team will be saved as a separate json in s3. - For each team in the NFL schedule the script will go to https://www.nfl.com/feeds-rs/coach/byTeam/
/ .json and save a json file for each coach for each season. The json file is saved by team, season, week. If the script is run on a weekly basis it will be able to log coaching changes that occur during the regular season.
Step 2
The time to process a single season, deconstruct each game file save each play stat and player json file could easily take over an hour. By using AWS Lambda this time can be reduced to minutes. For step 2 for each gameid saved in s3 will start an AWS process which will download the complete game json and save it in another s3 bucket. The only downside to this is each s3 prefix can only have one lambda trigger. Also Lambda functions can run for a maximum of 15 minutes, so it is a best practice to keep Lambda functions simple. It takes less than 30 seconds for Lambda to open each json file and download the game file and save it in the correct s3 folder. The code for this Lambda function is saved in the lambda_functions folder under the name gameids.py.
Step 3
For each full game saved in s3, Lambda will launch and deconstruct each game saving each play stat as a separate json file in s3. This function will execute a second task of saving each player from the game as a single json document in a separate json document. The code for this function can be viewed in the lambda_functions folder under the name gamesheet_decon.py.
Step 4
For each Player ID saved Lambda will save the Player json file into an s3 bucket in a format that is ready to load into the Redshift staging table.
Step 5
Once the initial data transformation from has taken place and the de-nested json files are in the staging s3 buckets, the process can be started in Apache Airflow. The data will be copied from s3 into the Redshift staging tables.
Step 6
Once the data has been moved from each bucket to the appropriate staging table, the staging tables will begin to populate the fact and dimension tables.
Step 7
After all the staging tables have populated the fact and dimension tables a data quality check is conducted, and Airlow will stop the process.
Lessons Learned/Final Thoughts
The goal of this project was to build a database from NFL endpoints. This database will allow people to conduct queries on players, teams, and coaches performances. This can be used by NFL fans as well as those who play fantasy football to help plan their team and track potential points. The primary tools for this project were Python, AWS Lambda, AWS s3, AWS Redshift, and Airflow. AWS Lambda was used to help preprocess data that could take hours if done sequentially, by using Lambda this data preprocessing was reduced to minutes. AWS s3 storage was used for the json files as the storage is cheap and easily connects to AWS Lambda and Redshift. AWS Redshift was used to store the data. By using a column store distributed database, data should be readily available and returned quickly. By using Airflow the ability to schedule the transfer of the data from S3 to staging tables and finally to the dimension and fact tables.
For me this project is bittersweet. After working with the NFL data for about a year, I finally found a way to easily move the data into a database which allowed for aggregate analysis only for the NFL to stop public access to the endpoints. This project allowed me to incorporate all the tools I had used in several other projects and was a great exercise.