
Project Background
For this project the fictional company Sparkify has grown past the initial databases created in the PostgreSQL-Data-Modeling Project and now the company needs a more robust database to store the ever increasing data. The goal of this project is to create a database inside of AWS Redshift and populate it from log files stored in an s3 Bucket. This project also introduces the concept of infrastructure as code. Part of the project entails creating a python script to launch a new AWS Redshift cluster.
The GitHub for this project is located here: Redshift-Data-Warehouse-Project
Project Datasets
As with the PostgreSQL-Data-Modeling, there are two datasets for this project. The Song data and the log data. Both of these datasets are stored in s3 buckets provided by Udacity.
Song Dataset
Each song in the song dataset is stored as a separate JSON file. These JSON files are stored in an s3 partition based on the first three letters of each song’s track ID. Below is an example provided by Udacity:
song_data/A/B/C/TRABCEI128F424C983.json song_data/A/A/B/TRAABJL12903CDCF1A.json
An example of the JSON format for each song is:
{“num_songs”: 1, “artist_id”: “ARJIE2Y1187B994AB7”, “artist_latitude”: null, “artist_longitude”: null, “artist_location”: “”, “artist_name”: “Line Renaud”, “song_id”: “SOUPIRU12A6D4FA1E1”, “title”: “Der Kleine Dompfaff”, “duration”: 152.92036, “year”: 0} </code></pre>
The data schema for this JSON is:
| Field | Data Type |
|---|---|
| num_songs | INT |
| artist_id | VARCHAR |
| artist_latitude | REAL |
| artist_longitude | REAL |
| artist_location | VARCHAR |
| artist_name | VARCHAR |
| song_id | VARCHAR |
| title | VARCHAR |
| duration | NUMERIC |
| year | INT |
Log Dataset
The logfiles for each day are stored in a JSON file. These JSON files are partitioned in s3 by year and month. An example of this formation is:
log_data/2018/11/2018-11-12-events.json log_data/2018/11/2018-11-13-events.json
Each JSON file is actually a JSON line formatted. In a JSON line file each line is a valid JSON object; however, this means the actual file itself cannot be treated as a JSON file. To avoid errors while reading this file into Python it is recommend to use pandas with the following format:
A sample of this log data in a dataframe is shown below:
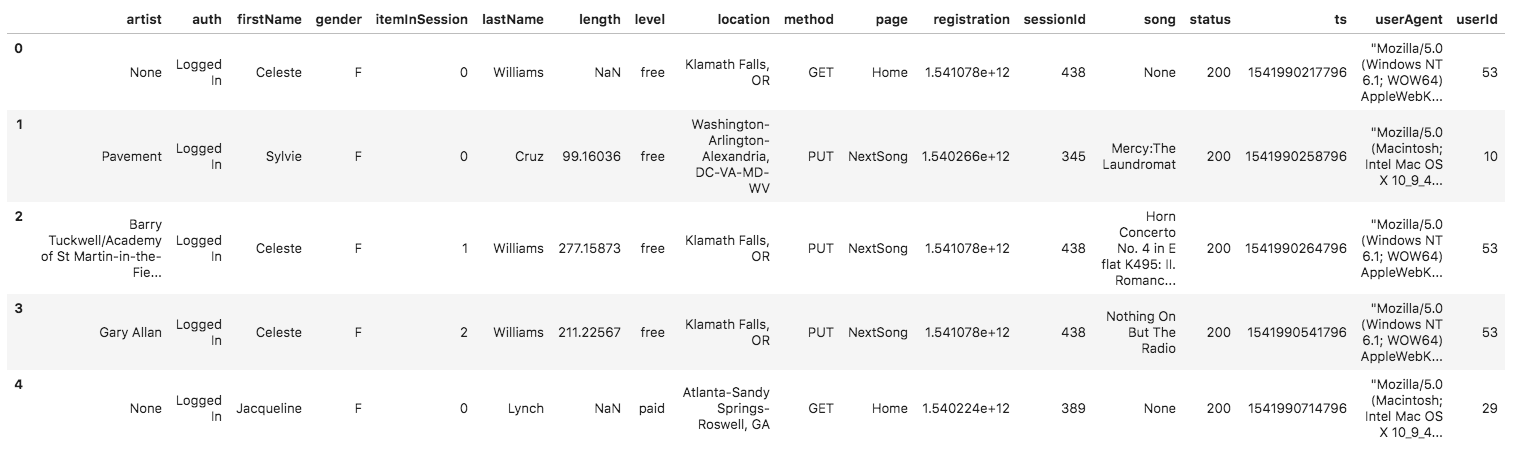
The data schema for the log dataset is:
| Field | Data Type |
|---|---|
| artist | VARCHAR |
| auth | VARCHAR |
| firstName | VARCHAR |
| gender | VARCHAR |
| itemInSession | INT |
| lastName | VARCHAR |
| length | REAL |
| level | VARCHAR |
| location | VARCHAR |
| method | VARCHAR |
| page | VARCHAR |
| registration | NUMERIC |
| sessionId | INT |
| song | VARHCHAR |
| status | INT |
| ts | TIMESTAMP |
| userAgent | VARCHAR |
| userId | INT |
Final Database Schema
Much like the PostgreSQL-Data-Modeling Project, the primary data model for this project will be a start schema. However, instead of reading data directly from the s3 buckets into the final database, this project will make use of a staging table to act as an intermediary between the s3 bucket and the final database.
The Staging Table
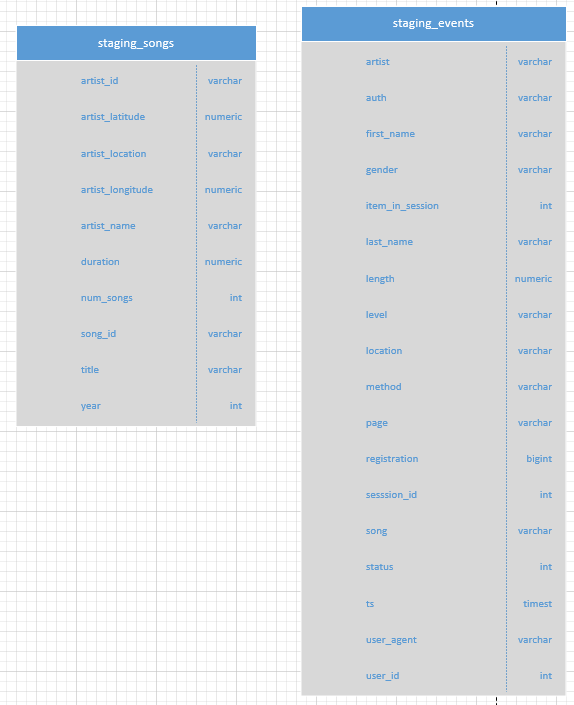
There are two staging tables staging_events and the staging_songs tables. These tables are to temporally hold data from the S2 Bucket before being transformed and inserted into the primary use tables.
The staging_songs table contains:
The staging_songs table contains:
| Field | Data Type |
|---|---|
| artist_id | VARCHAR |
| artist_latitude | NUMERIC |
| artist_location | VARCHAR |
| artist_longitude | NUMERIC |
| artist_name | VARCHAR |
| duration | FLOAT |
| num_songs | INTEGER |
| song_id | VARCHAR |
| title | VARCHAR |
| year | INTEGER |
The staging_events table contains:
| Field | Data Type |
|---|---|
| artist | VARCHAR |
| auth | VARCHAR |
| first_name | VARCHAR |
| gender | VARCHAR |
| item_in_session | INTEGER |
| last_name | VARCHAR |
| length | NUMERIC |
| level | VARCHAR |
| location | VARCHAR |
| method | VARCHAR |
| page | VARCHAR |
| registration | BIGINT |
| session_id | INTEGER |
| song | VARCHAR |
| status | INTEGER |
| ts | TIMESTAMP |
| user_agent | VARCHAR |
| user_id | INTEGER |
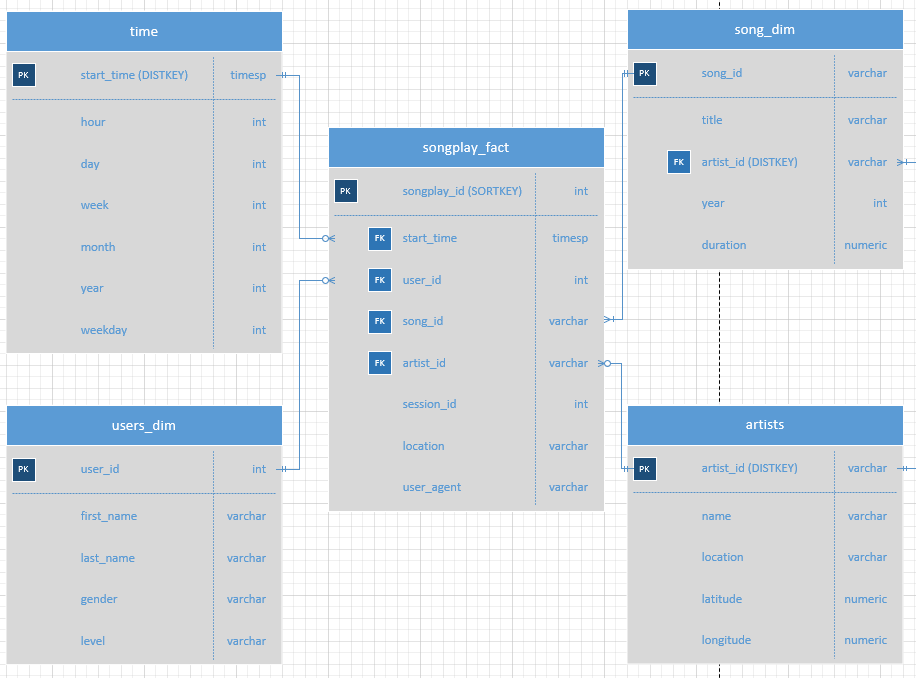
The use tables are the songplay_fact, time_dim, user_dim, song_dim, and artist_dim tables. These tables are in the
The time table which contains:
| Field | Data Type | Key | KEYDIST |
|---|---|---|---|
| start_time | TIMESTAMP | Primary | SORTKEY/DISTKEY |
| hour | INTEGER | ||
| day | INTEGER | ||
| week | INTEGER | ||
| month | INTEGER | ||
| year | INTEGER | ||
| weekday | INTEGER |
The users table which contains:
| Field | Data Type | Key | KEYDIST |
|---|---|---|---|
| user_id | INTEGER | Primary | |
| first_name | VARCHAR | ||
| last_name | VARCHAR | ||
| gender | VARCHAR | ||
| level | VARCHAR |
The songs table which contains:
| Field | Data Type | Key | KEYDIST |
|---|---|---|---|
| song_id | VARCHAR | Primary | |
| title | VARCHAR | ||
| artist_id | VARCHAR | Foreign Key | |
| year | INT | ||
| duration | NUMERIC |
The artists table which contains:
| Field | Data Type | Key | KEYDIST |
|---|---|---|---|
| artist_id | VARCHAR | Primary | DISTKEY |
| name | VARCHAR | ||
| location | VARCHAR | ||
| latitude | NUMERIC | ||
| longitude | NUMERIC |
The songplay table which contains:
| Field | Data Type | Key | KEYDIST |
|---|---|---|---|
| songplay_id | INT | Primary | SORTKEY |
| start_time | TIMESTAMP | Foreign Key | |
| user_id | INTEGER | Foreign Key | |
| song_id | VARCHAR | Foreign Key | |
| artist_id | VARCHAR | Foreign Key | |
| session_id | INT | ||
| location | VARCHAR | ||
| user_agent | VARCHAR |
Project Process
This project while similar to the PostgreSQL-Data-Modeling Project, the process for building and moving the data is different.
- Using the aws_setup.ipynb is used first to enter in the AWS credentials and start a Redshift cluster. The file used to store the AWS credentials and some cluster information is stored in the dwh.cfg. It is important to ensure the dwh.cfg file is added to the .gitignore file to avoid posting account credentials to a public repository.
- Next the create_tables.pyis run. This file will create the staging tables along with the final database table and associated relationships.
- Once the tables have been built the etl.py file is run. This file will:
- Copy the JSON files from the s3 bucket to the staging tables
- Insert the data from the staging tables into the correct table in the final database
- Ensure the data was correctly copied into the tables using the aws_data_test.ipynb
- If everything is correct the data and Redshift Clusters can be deleted using the last portion of the aws_setup.ipynb
Lessons Learned/Final Thoughts
I learned a couple important lessons during this project. The first is that your AWS credentials can be saved in your .ipynb_checkpoints file. I learned this after a push to my GitHub repository, were in about 15 seconds I have several emails from GitHub and Amazon, along with Amazon calling my phone number. There were several frantic minutes of removing tokens and deleting repositories. All in all it was a valuable lesson, that thankfully didn’t cost me anything but time.
The second part I really enjoyed was learning how to interact with AWS through pure code. This is where the infrastructure as code concept really hit home for me. Not only is this more convenient to start a cluster through some basic python code, it is also makes scaling infrastructure very easy. Through a simple code change a cluster can be started and stopped and can even be done based on conditions set in an if statement. This is a very powerful concept, and made me prioritize my learning of Docker, which I will discuss in a later blog post.
This is one of the projects where I started to incorporate the use of more complex systems. The use of s3 buckets, the use python to start and stop Redshift clusters, and staging tables. These are all concepts I have applied in other projects. Overall this was a challenging project as I had to learn new concepts. The easy part was moving the data from the staging table to the final database, the hard part was all the easy stuff before. But that is the point of Data Engineering, to quickly and efficiently move data from one place to another.